
Is AI Replacing Data Engineers in 2026? What the Data Shows

On this page
To understand the AI data engineer job market, we have to look at the hard statistics first. We cannot look at the market through pure optimism.
According to the Indeed Hiring Lab report tracking data through late last year, data and analytics job postings declined by 15.2% year-over-year. To put that into perspective, overall tech job postings dropped by 8.5% in the same period. This means data-related roles took a hit nearly twice as hard as the general tech sector.
At the same time, actual development habits have fundamentally shifted. A recent dbt Labs survey revealed that 70% of data practitioners now actively use AI for code development, and 50% rely on it for documentation. Tooling like GitHub Copilot and Cursor have become standard baseline requirements rather than cool developer extras.
On the surface, these numbers look scary. If data postings are down double digits and almost everyone is using AI to write code faster, the logical conclusion seems to be that companies need fewer humans. But if you look deeper into enterprise budgets, a different trend appears. A widespread market analysis showed that 40% of data teams actually expanded their size recently, and average data engineering budgets increased by roughly 30%.
How do we reconcile falling job postings with growing budgets and team expansions? Companies are no longer hiring armies of junior developers to manually scaffold basic pipelines. They are hunting for mid-level and senior engineers who can handle complex infrastructure, while using AI to handle the volume of work that used to require a much larger team. The baseline salary for these positions remains highly competitive, averaging around $130,000, with top-tier roles ranging between $120,000 and $160,000. The jobs exist, but the entry barrier has shifted upward.
Why data engineering tasks look "AI-suited" on paper
it's easy to see why people watching the tech industry from the outside assume data engineering will be completely automated. Historically, a massive portion of the job has been repetitive, structured, and predictable.
Consider the traditional Extract, Load, Transform (ELT) paradigm. A standard pipeline follows a very clear recipe:
Connect to an API or database source.
Extract records in a format like JSON or CSV.
Dump those records into a cloud data lake or warehouse like Snowflake or Databricks.
Run a SQL script to clean up timestamps, filter out null values, and join tables.
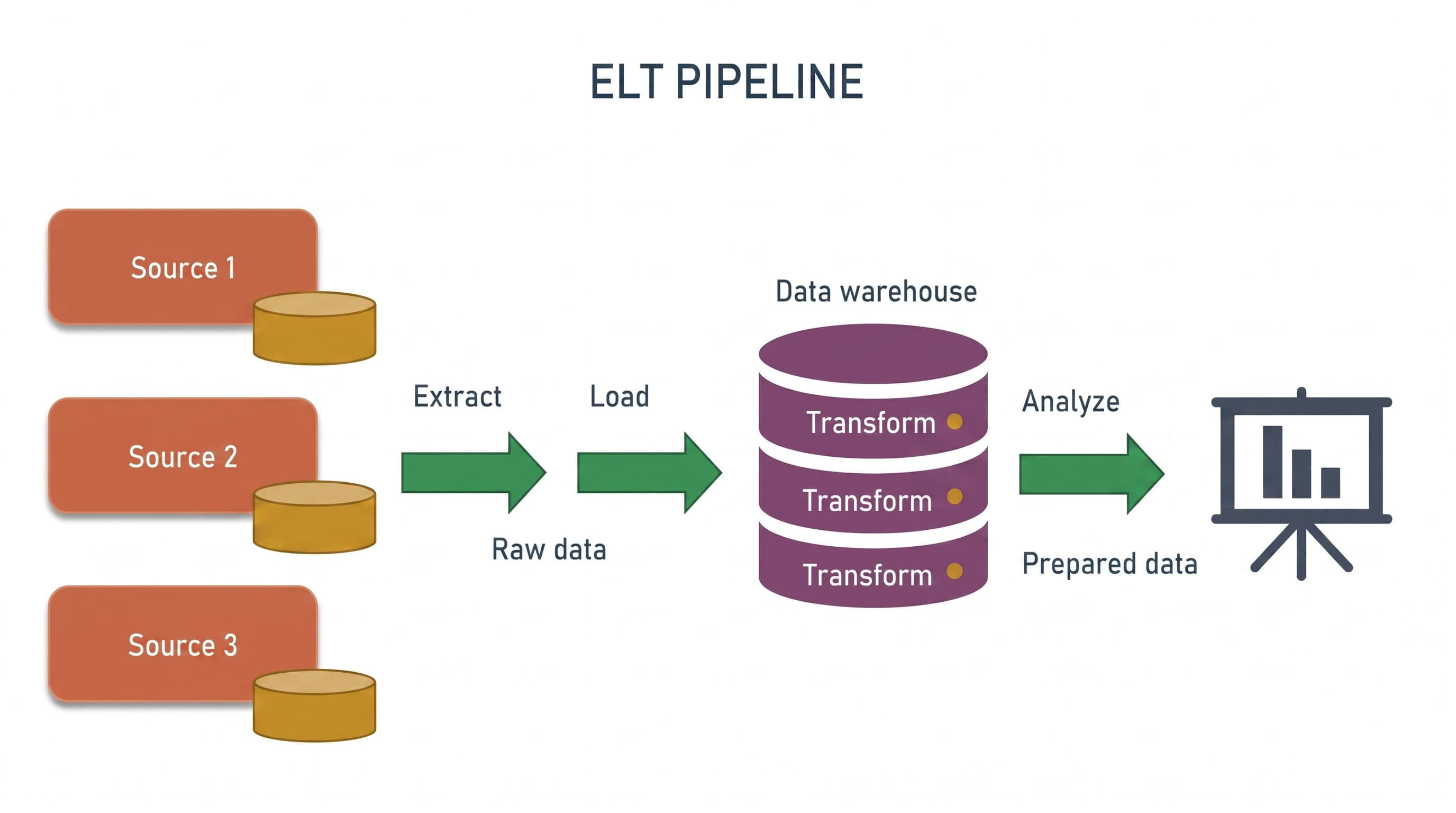
Large Language Models (LLMs) are exceptionally good at pattern matching and syntax generation. If you feed an AI the schema of a source database and the schema of your target warehouse, it can generate the required Python or SQL code almost instantly. Writing the basic scaffolding for a pipeline is a solved problem for AI.
Furthermore, the rise of agentic data engineering has pushed this automation even further. We are no longer just talking about "tab-completion" tools where an engineer copies and pastes a query from a chatbot. In 2026, autonomous systems like Databricks Genie Code and Snowflake Cortex Code operate directly within the secure boundaries of corporate data platforms. They can write the code, execute it against the warehouse, read the error logs when it fails, and iteratively fix their own syntax errors without human intervention.
When an executive sees an AI agent build an entire data ingestion workflow from a simple English prompt, their immediate thought is often: "Why am I paying a team of engineers to do this?"
What's actually being automated vs. what isn't
The flaw in that executive logic is confusing code generation with system ownership. Writing the initial lines of a data pipeline is only about 20% to 30% of the actual job. The remaining 70% is where human engineers earn their paychecks, and it involves problems that AI agents completely struggle to solve.
To understand why data engineering is not disappearing, we need to draw a clear line between what can be automated and what requires human design.
Task Type | What AI Can Do Perfectly | Where AI Fails (Human Required) |
Pipeline Creation | Writing boilerplate Python scripts, standard SQL joins, and basic API connectors. | Designing scalable architecture, selecting table formats (like Apache Iceberg), and configuring orchestration. |
Debugging | Fixing syntax errors, resolving obvious type mismatches, and parsing basic logs. | Resolving silent logical errors, tracing upstream data corruption, and handling hidden schema drift. |
Data Quality | Writing unit tests, applying standard null checks, and formatting documentation. | Establishing data contracts between engineering teams and cross-functional business stakeholders. |
The Reality of Pipeline Maintenance
Imagine an AI agent writes a flawless pipeline to pull sales data from a third-party CRM. Three weeks later, the CRM vendor changes their API payload without warning. The pipeline breaks silently because the data keeps flowing, but a crucial currency field is now nested inside a new JSON object.
An AI agent looking at the logs might see successful HTTP 200 codes and assume everything is fine. A human engineer, however, notices that the downstream executive dashboard is suddenly reporting millions of dollars in missing revenue. Finding that silent failure requires deep domain context, understanding human intent, and investigating messy, real-world dependencies.
Architecture and State Management
AI lacks the capacity for long-term strategic judgment. An AI tool can write a SQL query quickly, but it does not know whether your company should build a decentralized data mesh or a unified data fabric. It does not know if a streaming framework like Apache Flink makes financial sense for your business case, or if a standard hourly batch process using Apache Airflow is more cost-effective. AI excels at executing micro-tasks but fails completely at managing macro-systems.
The split forming - speed with quality vs. massive technical debt
Because AI makes code generation free, the data engineering jobs 2026 landscape is splitting into two different types of data teams.
Team A: The AI-Amplified Engineers
The first group consists of engineering teams that treat AI as a massive leverage tool. They use coding agents to clear out the boring boilerplate work. Instead of spending five hours writing repetitive SQL transformations, they let an agent handle it in five minutes.
This frees up the human engineers to focus on high-value initiatives:
Platform Engineering: Building reusable, self-serve internal data platforms so that analysts can safely access data without breaking the underlying systems.
Data Contracts: Negotiating strict agreements with software development teams to guarantee that upstream application changes do not break downstream data systems.
AI Infrastructure: Setting up the real-time retrieval-augmented generation (RAG) pipelines and vector databases that modern enterprise AI applications require to function.
These teams use AI to move incredibly fast while maintaining strict guardrails, automated testing, and clean data governance.
Team B: The Technical Debt Factory
The second group consists of teams that use AI carelessly. Software developers, product managers, or untrained analysts use LLMs to spin up dozens of unmonitored data pipelines to feed their specific needs.
Because nobody is managing the overarching architecture, these environments quickly turn into chaos. Duplicate pipelines pull the exact same data multiple times, causing cloud infrastructure bills to skyrocket. Undocumented, messy code runs rampant, and data quality degrades rapidly. When an AI system consumes bad, ungoverned data, it outputs bad decisions at scale.
Companies that make this mistake quickly find out that "free code" actually costs a lot of money to keep running. Eventually, they have to stop building new things and hire experienced data engineers to fix the mess, clean up the confusing code, and make sure their data is correct again.
What this means if you're breaking into the field right now
If you are currently transitioning into data engineering or looking for your first junior role, this new reality can feel intimidating. The days of landing a six-figure job just by knowing basic Python syntax and how to write a SELECT statement are over. But this does not mean the door is closed. It simply means your strategy has to adapt.
First, stop focusing your portfolio projects entirely on simple ETL pipelines. A GitHub repository filled with basic scripts that copy data from a public API into a Postgres database no longer impresses hiring managers. They assume an AI wrote it for you, and honestly, an AI could have.
Instead, build projects that showcase system design, reliability, and governance. Show that you know how to handle failures. Build a pipeline that explicitly includes data validation checks using tools like Great Expectations. Create a system that handles schema drift gracefully and alerts you when an upstream source changes unexpectedly.
Focus heavily on the core, unchanging fundamentals of the field. Python and SQL are still the undeniable foundations of data work. Market data shows that Python appears in 70% of data engineering job descriptions, and SQL follows closely at 69%. While SQL mentions dropped slightly from 79% last year, largely because AI can write basic queries easily, understanding the underlying database theory, indexing, and query optimization remains completely essential.
To help you navigate this transition, check out our comprehensive 60-Day Roadmap to Become a Data Engineer with Python. It lays out a step-by-step path focusing on the deep architectural skills that AI cannot replicate. Once you have the roadmap down, use our Junior Data Engineer Skills Checklist to audit your current portfolio and make sure you are building projects that prove you can manage entire systems, ndels will grow exponentially.
Frequently Asked Questions
Quick answers to common questions about this article.
Will data engineering exist in 5 years?
Will data engineering exist in 5 years?
Yes, but it will look much more like software engineering and platform architecture than traditional data loading. The task of manually moving data will be almost completely automated. The task of ensuring that data is secure, high-quality, legally compliant, and structured efficiently for machine learning models will grow exponentially.
Should I still learn SQL and Python?
Should I still learn SQL and Python?
Absolutely. Saying you shouldn't learn SQL or Python because AI can write it is like saying an architect shouldn't learn structural physics because CAD software handles the calculations. You cannot debug an AI's output if you do not understand the underlying language. If you want a safe place to practice your query logic and build muscle memory, spend some time working through practical scenarios in our interactive SQL Playground.
What skills matter more now than they did a few years ago?
What skills matter more now than they did a few years ago?
System architecture, cloud cost optimization, streaming data processing (using tools like Kafka or Flink), and data governance (such as implementing data contracts and lineage tracking). Understanding how to build data infrastructure specifically tailored to feed machine learning models and LLMs is also incredibly high in demand.
The Path Forward
The tech industry loves dramatic narratives. The reality of the AI data engineer job market is far less about absolute replacement and far more about evolution. AI is taking over the tedious, repetitive parts of data management, leaving the complex, strategic, and genuinely interesting challenges to human engineers.
If you are ready to stop worrying about the hype and start building a resilient, long-term technical career, focus on the deeper parts of the craft. Learn how distributed systems work, understand how to design clean databases, and practice managing infrastructure as code.
Take the first structured step today by diving into our full 60-Day Roadmap post, check the Junior DE Skills Checklist, and start sharpening your fundamental database skills inside our SQL Playground. The field isn't dying, it's just growing up.
More from Shaik Noor

Linux & Unix Commands Every Informatica Support Engineer Must Know
Jun 28, 2026 · 7 min read
Why the Salesforce + Informatica Merger is the Key to Hallucination-Free AI
Jun 21, 2026 · 5 min read

Beyond Autocomplete: The Rise of CLI-First AI Coding Agents
Jun 17, 2026 · 5 min read